 官方网站-首页官方网站-首页
官方网站-首页官方网站-首页你是不是也遇到过这样的情况:问AI一个问题,它给了你一个特别详细、丰富,看上去好有逻辑的答案。但当我们去核实时,却发现这些信息完全是虚构的?
这就是著名的“AI幻觉”现象。

图源:河森堡新浪微博
为什么会出现AI幻觉呢?今天就让我们一起来揭开这个谜题。
为什么会出现AI幻觉?
AI幻觉指的是AI会生成看似合理但实际(jì)确(què)实(shí)错(cuò)误(wù)的(de)信(xìn)息(xi),最(zuì)常(cháng)见(jiàn)的(de)表(biǎo)现(xiàn)就(jiù)是(shì)会(huì)编(biān)造(zào)一(yī)些(xiē)不(bù)存(cún)在(zài)的(de)事(shì)实(shí)或(huò)者(zhě)细(xì)节(jié)。
就(jiù)像(xiàng)在(zài)考(kǎo)试(shì)时(shí)遇(yù)到(dào)不(bù)会(huì)的(de)题(tí)目(mù),我(wǒ)们(men)会(huì)试(shì)图(tú)用(yòng)已(yǐ)知(zhī)的(de)知(zhī)识(shi)去(qù)推(tuī)测(cè)答(dá)案(àn)一样。AI在遇到信息缺失(shī)或(huò)不(bù)确(què)定(dìng)的(de)情(qíng)况(kuàng)时(shí),会(huì)基(jī)于(yú)自己的“经验”(训练数据)进行填补和推理。
这不是因为它想要欺骗我们,而是因为它在试图用自己理解的模式来完成这个任务。
1
基于统计关系的预测
因为AI(尤其是像ChatGPT这样的语言模型)通过大量的训练数据学习文字之间的统计关系。它的核心目标是根据上下文预测最可能出现的下一个词,并不是对问题或内容进行真正的理解。所以 AI本质上是通过概率最大化来生成内容,而不是通过逻辑推理来生成内容的。
简单来说,AI就像(xiàng)是(shì)一(yī)个(gè)博(bó)览(lǎn)群(qún)书(shū)的(de)智(zhì)者(zhě),通(tōng)过(guò)学(xué)习(xí)海(hǎi)量(liàng)的(de)文本(běn)和(hé)资(zī)料(liào)来(lái)获(huò)取(qǔ)知(zhī)识(shi)。但(dàn)是(shì)它(tā)并(bìng)不(bù)是(shì)真(zhēn)正(zhèng)理(lǐ)解(jiě)这(zhè)些(xiē)知(zhī)识(shi),而(ér)是(shì)通(tōng)过(guò)找(zhǎo)到(dào)文字(zì)之(zhī)间(jiān)的(de)统(tǒng)计(jì)关系(xì)和(hé)模(mó)式(shì)来(lái)“预(yù)测”下一个最合适的词。即 AI 是根据之前学到的大量例子,来猜测接下来最有可能出现的词。
不过有时候,模型也会“猜错”。如果前面出(chū)现(xiàn)一(yī)点(diǎn)偏(piān)差(chà),后(hòu)面(miàn)的(de)内(nèi)容(róng)就(jiù)会(huì)像(xiàng)滚(gǔn)雪(xuě)球(qiú)一(yī)样(yàng)越(yuè)滚(gǔn)越(yuè)大(dà)。这(zhè)就(jiù)是(shì)为(wèi)什(shén)么(me)AI有(yǒu)时(shí)会(huì)从(cóng)一(yī)个(gè)小(xiǎo)错(cuò)误(wù)开(kāi)始(shǐ),最(zuì)后(hòu)编(biān)织(zhī)出(chū)一(yī)个(gè)完(wán)全虚(xū)构的故事。
2
训练数据的局限性
由于AI并没有真实世界的体验,它的所有“认知”都来自训练数据。可是训练数据不可能包含世界上所有的信息,有时候甚至还会包含错误信息。这就像是一个人只能根据(jù)自(zì)己(jǐ)读(dú)过(guò)的(de)书(shū)来(lái)回(huí)答(dá)问(wèn)题(tí),如(rú)果(guǒ)书(shū)里(lǐ)有(yǒu)错误信息,或者某些领域的知识缺失,就容易产生错误的判断。举个例子:早期AI幻觉较大的时候,可能会出现AI学过“北京是中国的首都”和“巴黎有埃菲尔铁塔”这两个知识点。当我们问它“北京有什么著名建筑”时,它可能会把这些知识错误地混合在一起,说“北京有埃菲尔铁塔”。
3
过拟(nǐ)合(hé)问(wèn)题(tí)
因(yīn)为(wèi)大模型的训练参数量非常庞大,大模型会在训练数据上产生“过拟合”的问题。即因为记住了太多错误或者无关紧要的东西,从而让 AI对训练数据中的噪声过于敏感,最终导致幻觉产生。
4
有限的上下文窗口
受限于技术原因,虽然现在大模型的上下文窗口越来越大(比如可以处理64k或128k个tokens),但它们仍然是在一个有限的范围内理解文本。这就像是隔着一个小窗口看书,看不到整本书的内容,容易(yì)产(chǎn)生(shēng)理(lǐ)解(jiě)偏(piān)差(chà)。
5
生(shēng)成(chéng)流(liú)畅(chàng)回(huí)答(dá)的(de)设(shè)计(jì)
现(xiàn)在(zài)很(hěn)多(duō)大(dà)模(mó)型(xíng)被(bèi)设(shè)计(jì)成(chéng)要(yào)给(gěi)出(chū)流(liú)畅(chàng)的(de)回(huí)答(dá),当(dāng)它(tā)对(duì)某(mǒu)个(gè)问(wèn)题(tí)不(bù)太(tài)确(què)定(dìng)时(shí),与(yǔ)其(qí)说(shuō)“我(wǒ)不(bù)知(zhī)道(dào)”,它(tā)更(gèng)倾(qīng)向(xiàng)于(yú)基(jī)于(yú)已(yǐ)有(yǒu)知(zhī)识(shi)编(biān)造(zào)看(kàn)起(qǐ)来(lái)合理的答案。上面的(de)种(zhǒng)种(zhǒng)情(qíng)况(kuàng)叠(dié)加(jiā)在(zài)一(yī)起(qǐ),造(zào)成(chéng)了(le)现(xiàn)在(zài)非(fēi)常(cháng)严(yán)重(zhòng)的(de)AI幻(huàn)觉(jué)问(wèn)题(tí)。

图(tú)库(kù)版(bǎn)权(quán)图(tú)片(piàn),转(zhuǎn)载(zài)使(shǐ)用(yòng)可(kě)能(néng)引(yǐn)发(fā)版(bǎn)权(quán)纠(jiū)纷(fēn)
如(rú)何(hé)才(cái)能(néng)降(jiàng)低AI幻觉?
AI看起来很方便,但 AI 一本正经的“胡说八道”有时候真的让人非常头疼,给的信息经常需要反复核实,有时反而不如直接上网搜索来得实在。那么,如(rú)何应对AI幻觉呢?我们总结了下面这些方法帮助大家。
1
优化提问
想要获得准确答案,提问方式很关键。与AI交流也(yě)需(xū)要(yào)明(míng)确(què)和(hé)具(jù)体(tǐ),避(bì)免(miǎn)模(mó)糊(hu)或(huò)开(kāi)放性的问题,提问越具体、清晰,AI的回答越准确。同时,我们在提问的时候要提供足够多的上下文或背景信息,这样也可以减少AI胡乱推测的可能性。总结成提示词技巧就是下面四种问法:
1.设(shè)定(dìng)边(biān)界(jiè):“请(qǐng)严(yán)格(gé)限(xiàn)定(dìng)在(zài)2022年(nián)《自(zì)然(rán)》期(qī)刊(kān)发(fā)表(biǎo)的(de)研(yán)究(jiū)范(fàn)围(wéi)内(nèi)”;
示(shì)例(lì):“介(jiè)绍(shào)ChatGPT的(de)发(fā)展(zhǎn)历(lì)程(chéng)”→“请(qǐng)仅(jǐn)基(jī)于(yú)OpenAI官(guān)方(fāng)2022-2023年(nián)的(de)公(gōng)开(kāi)文档(dàng),介(jiè)绍(shào)ChatGPT的(de)发(fā)展(zhǎn)历(lì)程(chéng)”
2.标(biāo)注(zhù)不(bù)确(què)定(dìng):“对(duì)于(yú)模(mó)糊(hu)信(xìn)息(xi),需(xū)要(yào)标注‘此处为推测内容’”;
示例:“分析特斯拉2025年的市场份额”→“分析特斯拉2025年的市场份额,对于非官方数据或预测性内(nèi)容(róng),请(qǐng)标(biāo)注(zhù)[推测内容]”
3.步骤拆解:“第一步列举确定的事实依据,第二步展开详细分析”;
示例:“评估人工智能对就业的影响”→“请分两步评估AI对就业的影响:
1)先列出目前已发生的具体影响案例;
2)基于这些案例进行未来趋势分析”。
4.明确约束:明确告诉AI要基于已有事实回答,不要进行推测。
示例:“预测2024年房地产市场走势”→“请仅基于2023年的实际房地产数据和已出台的相关政策进(jìn)行(xíng)分析,不要加入任何推(tuī)测(cè)性内容”。
2
分批输出
因为AI内容是根据概率来进行生成的,一次性生成的内容越多,出现AI幻觉的概率就越大,我们可以主动限制它的输出数量。比如:如果我要写一篇长文章,就会这么跟AI说:“咱们一段一段来写,先把开头写好。等这部分满意了,再继续写下一段。”这样不仅内容更准确,也更容易把控生成内容的质量。
3
交(jiāo)叉(chā)验(yàn)证(zhèng)
想(xiǎng)要(yào)提(tí)高(gāo)AI回(huí)答(dá)的(de)可(kě)靠(kào)性(xìng),还(hái)有(yǒu)一(yī)个(gè)实(shí)用(yòng)的(de)方(fāng)法(fǎ)是(shì)采用(yòng)“多(duō)模(mó)型(xíng)交(jiāo)叉(chā)验(yàn)证(zhèng)”。使(shǐ)用(yòng)的(de)一(yī)个(gè)AI聚(jù)合(hé)平(píng)台(tái):可(kě)以(yǐ)让(ràng)多(duō)个(gè)AI模(mó)型(xíng)同(tóng)时(shí)回(huí)答(dá)同(tóng)一(yī)个(gè)问(wèn)题(tí)。当(dāng)遇(yù)到(dào)需(xū)要(yào)严(yán)谨(jǐn)答(dá)案(àn)的(de)问(wèn)题(tí)时(shí),就会启动这个功能,让不同的大模型一起参与讨论,通过对比它们的答案来获得更全面的认识。
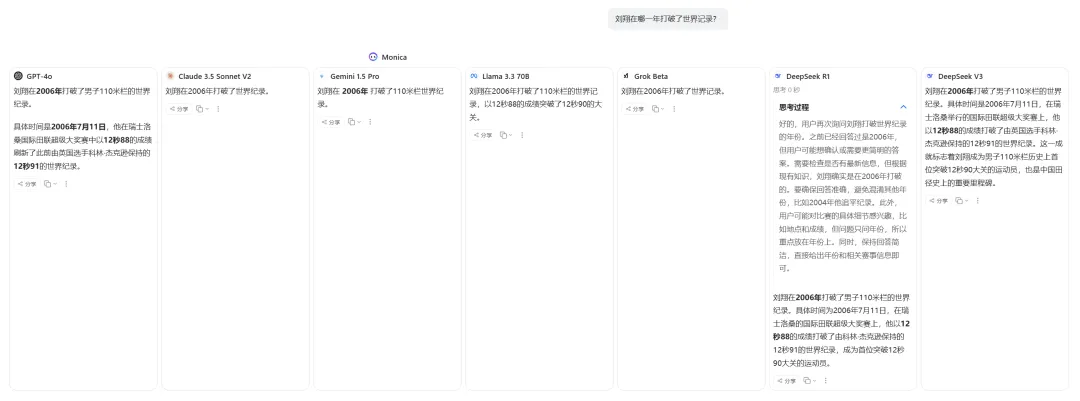
点击可放大,图片来源:作者提供
再比如纳米AI搜索平台的“多模型协作”功能,它能让不同的AI模型各司其职,形成一个高效的协作团队。让擅长推理的DeepSeekR1负责分析规划,再由通义千问进行纠错补充,最后交给豆包AI来梳理总结。这种“专家组”式的协作模式,不仅能提升内容的可信度,还能带来更加全面和深入的见解。
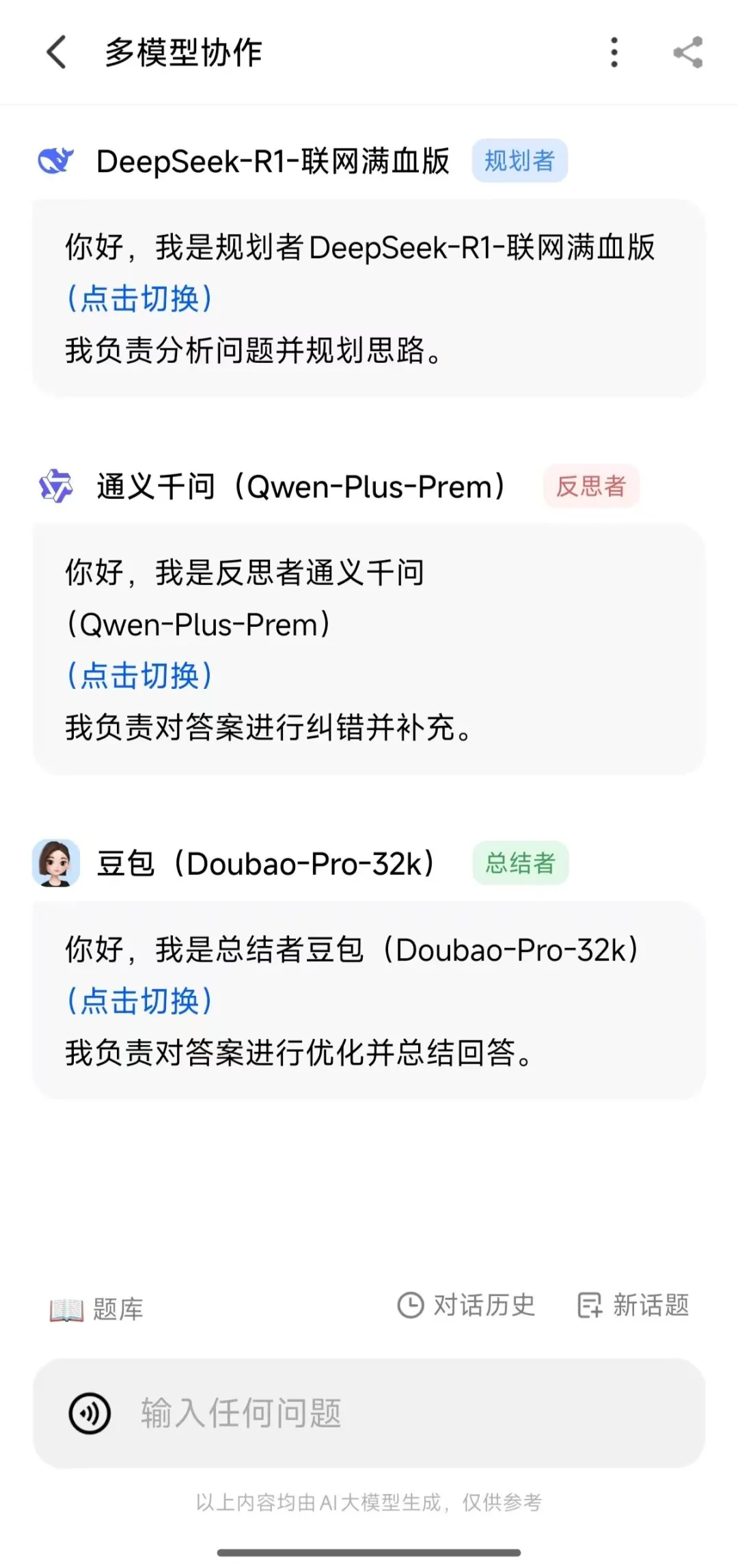
图源:作者提供
4
RAG技术
AI是一个聪明但健忘的人,为了让他表现更靠谱,我们可以给他配一个超级百科全书,他可以随时查阅里面的内容来回答问题。这本“百科全书”就是RAG的核心,它让AI在回答问题之前,先从可靠的资料中找到相关信息,再根据这些信息生成答案。这样一来,AI就不容易“胡说八道”了。目前RAG技术多用在医疗、法律、金融等专业领域,通过构建知识库来提升回答的准确性。当然实际使用中像医疗、法律、金融这样的高风险领域,AI生成的内容还是必须要经过专业人士的审查的。
5
巧用AI幻觉
最后再说一个AI幻觉的好处。
很多时候AI幻觉也是天马行空的创意火花!就像一个异想天开的艺术家,不受常规思维的束缚,能蹦出令人惊喜的点子。
看看DeepSeek就知道了,它确实比ChatGPT和Claude更容易出现幻觉,但是今年DeepSeek能火得如此出圈也离不开其强大的创造能力。
有时候与其把AI幻觉当成缺陷,不如把它看作创意的源泉!在写作、艺术创作或头脑风暴时,这些“跳跃性思维”反而可能帮我们打开新世界的大门。

图库版权图片,转载使用可能引发版权纠纷
AI幻觉的本质——AI在知识的迷雾中,有时会创造出看似真实,实则虚幻的“影子”。但就像任何工具一样,关键在于如何使用。
当我们学会用正确的方式与AI对话,善用它的创造力,同时保持独立思考,AI就能成为我们得力的助手,而不是一个“能言善辩的谎言家”。
毕竟,在这个AI与人类共同进步的时代,重要的不是责备AI的不完美,而是学会与之更好地协作。
策划制作
作者丨田威 AI工具研究者
审核丨于旸 腾讯玄武实验室负责人





